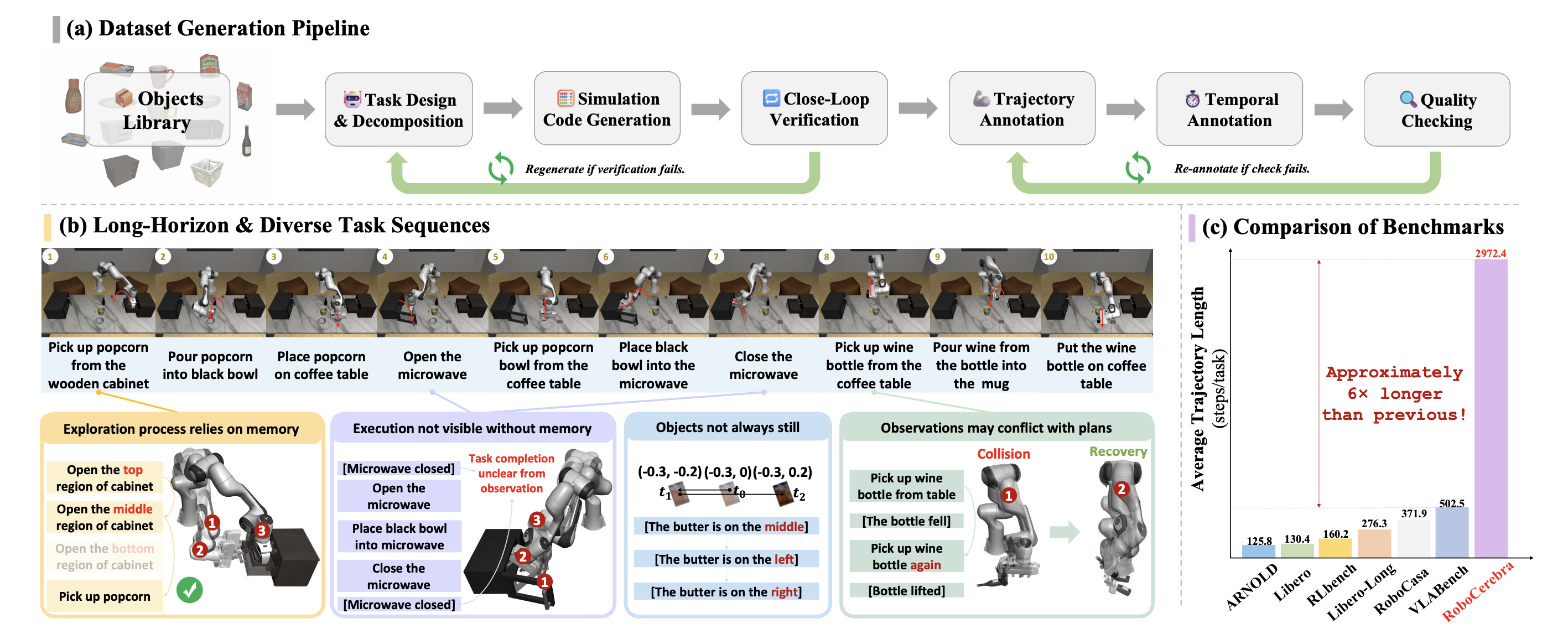
Recent advances in vision-language models (VLMs) have enabled instruction-conditioned robotic systems with improved generalization. However, most existing work focuses on reactive System 1 policies, underutilizing VLMs’ strengths in semantic reasoning and long-horizon planning. These System 2 capabilities—characterized by deliberative, goal-directed thinking—remain underexplored due to the limited temporal scale and structural complexity of current benchmarks. To address this gap, we introduce RoboCerebra, a benchmark for evaluating high-level reasoning in long-horizon robotic manipulation. RoboCerebra includes: (1) a large-scale simulation dataset with extended task horizons and diverse subtask sequences in household environments; (2) a hierarchical framework combining a high-level VLM planner with a low-level vision-language-action (VLA) controller; and (3) an evaluation protocol targeting planning, reflection, and memory through structured System 1–System 2 interaction. The dataset is constructed via a top-down pipeline, where GPT generates task instructions and decomposes them into subtask sequences. Human operators execute the subtasks in simulation, yielding high-quality trajectories with dynamic object variations. Compared to prior benchmarks, RoboCerebra features significantly longer action sequences and denser subtask annotations, forming a more rigorous testbed for evaluating System 2 reasoning.
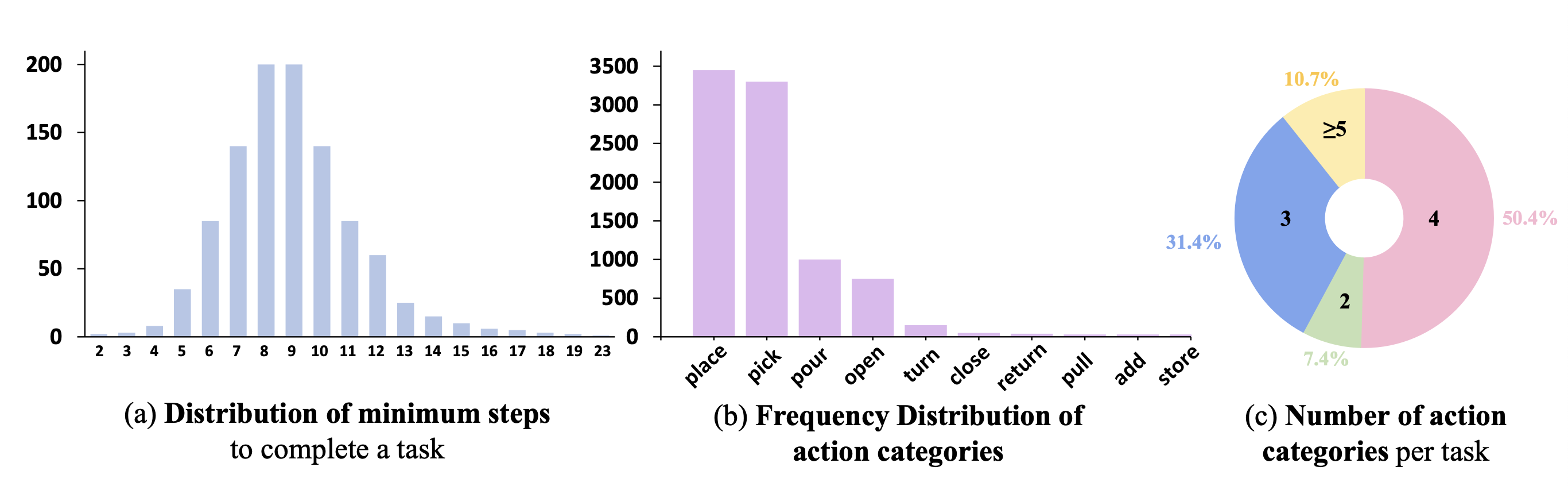
RoboCerebra contains 1,000 human-annotated trajectories across 100 task variants, each spanning up to 3,000 simulation steps. Tasks cover everyday household activities (e.g., preparing drinks, tidying groceries) and are annotated with fine-grained subtask boundaries, temporal segments, and dynamic scene variations.
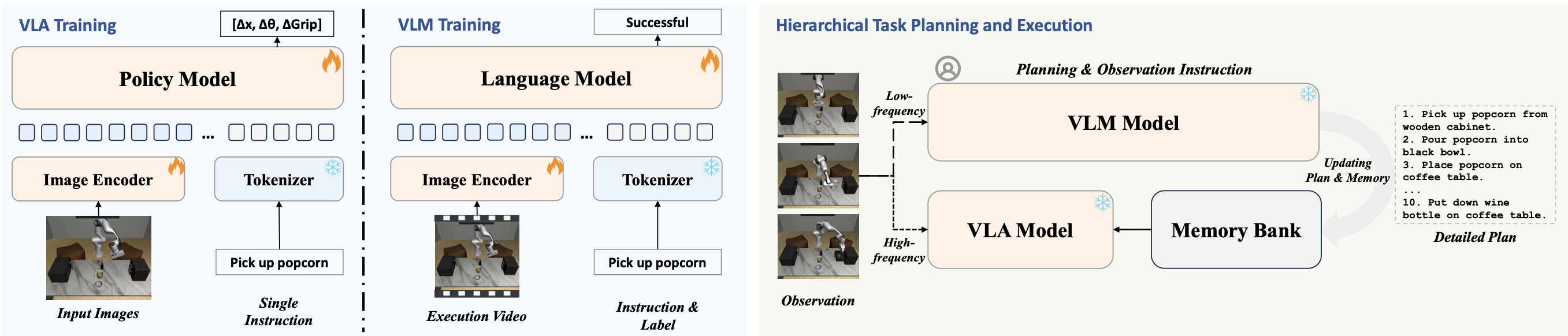
At inference time, the VLM parses a high-level task instruction into a sequence of step-level subgoals, which are stored in a memory bank. The VLA continuously queries the active subgoal and executes corresponding low-level actions based on high-frequency visual observations. Concurrently, the VLM periodically attends to recent observations to monitor execution progress. Upon detecting subgoal completion or deviation, it updates the memory with the next subgoal or issues a refined instruction. This closed-loop coordination preserves temporal abstraction while ensuring reactive control, enabling robust and interpretable performance in long-horizon tasks.
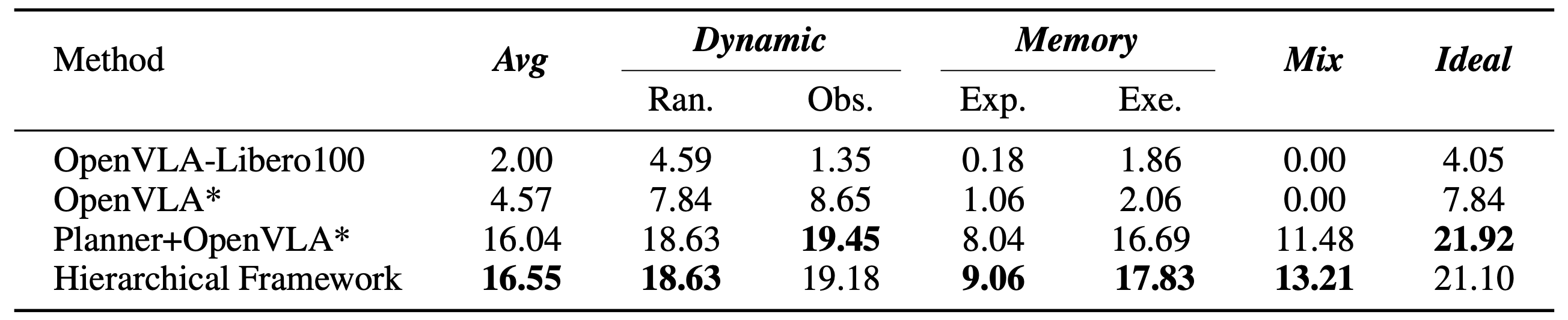
We evaluate each method over 600 rollouts (60 tasks × 10 trials). For fair comparison across planning models, we define a set of anchor points that determine when System 1 transitions between subgoals. These anchor-aligned transitions decouple step-switching from the model, allowing consistent temporal granularity across models.
@article{han2025robocerebra,
title={RoboCerebra: A Large-scale Benchmark for Long-horizon Robotic Manipulation Evaluation},
author={Han, Songhao and Qiu, Boxiang and Liao, Yue and Huang, Siyuan and Gao, Chen and Yan, Shuicheng and Liu, Si},
journal={arXiv preprint arXiv:2506.06677},
year={2025}
}